[Kubernetes] EKS Cluster AutoScaling 완전 정복(Feat: Terraform, Helm, HPA, Jmeter)
운덩하는 개발자2024. 3. 16.
반응형
Kubernetes 환경의 Node에는 용량에 제한이 있어, 더 이상 생성될 수 없는 Pod는 Pending 상태가 되는데
이를 해결하기 위한 방법으로 Node의 리소스를 늘리거나 수를 조절하는 솔루션을 적용하게 된다
이 솔루션에 CA(Cluster AutoScaling)과 Karpenter가 있는데 오늘은 CA에 대해서 알아보도록 하자
Cluster AutoScaling 이란?
Kubernetes에서클러스터 내 리소스 사용량에 기반하여 노드의 수를 유연하게 조절하는 기술이다
공식문서에서는 pod가 실패하거나 다른 노드로 다시 예약될 때 클러스터의 노드 수를 유연하게 조절한다고 소개하고 있다.
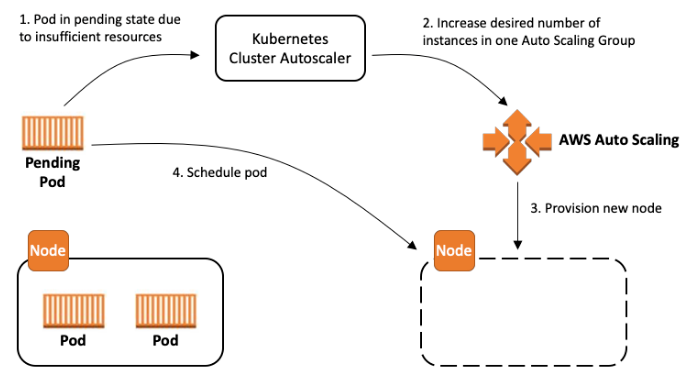
Cluster AutoScaling 동작과정
1) Pod가충분한 리소스를 할당 받지 못해 Pending 상태임을 감지
모니터링:
CA는 정기적으로 클러스터 상태를 검사합니다. 이 때, 리소스 부족으로 스케줄링되지 않은 Pod들을 발견
API 서버 접근:
CA는 쿠버네티스 API 서버와 통신하여, 스케줄링되지 않은 Pod들의 목록을 가져온다
리소스 요구사항 분석:
각 Pending 상태의 Pod가 요구하는 CPU, 메모리 등의 리소스 양을 분석
2) CA(Cluster AutoScaler)가 Auto Scaling 그룹의 Desired capacity를 증가시킨다.
노드 추가 필요성 결정:
CA는 분석 결과, 현재 클러스터 내에서 해당 Pod들을 수용할 수 있는 충분한 리소스가 없다고 판단
Desired Capacity 계산:
필요한 추가 노드 수를 계산하여, Auto Scaling 그룹의 Desired Capacity를 조정할 새로운 값으로 설정
3) AWS Auto Scaling 그룹은 CA로부터 받은 Desired Capacity 값에 따라 자동으로 노드를 추가
Auto Scaling 그룹에 명령 전송:
CA는 AWS Auto Scaling API를 호출하여, 계산된 Desired Capacity 값을 업데이트
노드 인스턴스 시작:
Auto Scaling 그룹은 설정된 Desired Capacity에 따라 필요한 수의 EC2 인스턴스를 자동으로 시작
노드 등록:
시작된 EC2 인스턴스는 쿠버네티스 클러스터에 자동으로 노드로 등록.
이 과정에는 인스턴스가 쿠버네티스 클러스터에게 자신을 소개하고, kubelet이 API 서버에 등록하는 작업이 포함된다
4) kube-scheduler를 통해서 신규 노드로 Pending 상태의 파드들을 스케줄링
스케줄링 재시도:
새로운 노드가 클러스터에 추가되면, kube-scheduler는 Pending 상태의 Pod들에 대해 스케줄링을 재시도
리소스 할당:
kube-scheduler는 각 Pod의 리소스 요구사항과 새로운 노드의 리소스 용량을 비교하여, 적절한 노드에 Pod를 할당
Pod 배치:
할당된 노드에서 kubelet은 쿠버네티스 API 서버로부터 Pod 실행 명령을 받고, 컨테이너를 시작
상태 업데이트:
Pod가 성공적으로 시작되면, kubelet은 Pod의 상태를 Running으로 업데이트하고, 쿠버네티스 API 서버에 반영
구현
1.Terraform
테라폼에서 클러스터 내에 ca관련 정책과 역할을 배포하고 헬름 차트를 통해 HPA(Horizontal Pod Autoscaler)와 HPA를 위한 MetricServer와 CA를 배포하는 코드다
# C:\AMZMall_Dev_GitOps\terraform\examples\complete\ca.tf
# CA IAM Role을 위한 정책 설정
resource "aws_iam_policy" "ca_iam_policy" {
name = "ca_iam_policy-${var.infra_name}"
description = "ca policy"
policy = file("${path.module}/policy/ca_iam_policy.json")
}
data "aws_iam_policy_document" "ca_assume_role_policy" {
statement {
actions = ["sts:AssumeRoleWithWebIdentity"]
effect = "Allow"
principals {
type = "Federated"
identifiers = ["arn:aws:iam::${data.aws_caller_identity.current.account_id}:oidc-provider/${replace(data.aws_eks_cluster.cluster.identity[0].oidc[0].issuer, "https://", "")}"]
}
condition {
test = "StringEquals"
variable = "${replace(data.aws_eks_cluster.cluster.identity[0].oidc[0].issuer, "https://", "")}:sub"
values = ["system:serviceaccount:kube-system:cluster-autoscaler"]
}
}
}
resource "aws_iam_role" "ca_iam_role" {
name = "${var.cluster_name}-ca-role"
assume_role_policy = data.aws_iam_policy_document.ca_assume_role_policy.json
tags = {
"Name" = "${var.cluster_name}-ca-role"
}
}
resource "aws_iam_role_policy_attachment" "ca_iam_policy_attach" {
role = aws_iam_role.ca_iam_role.name
policy_arn = aws_iam_policy.ca_iam_policy.arn
}
# Metrics Server Helm Release
resource "helm_release" "metrics_server" {
namespace = "kube-system"
name = "metrics-server"
chart = "metrics-server"
repository = "https://kubernetes-sigs.github.io/metrics-server/"
}
resource "kubernetes_service_account" "cluster_autoscaler" {
metadata {
name = "cluster-autoscaler"
namespace = "kube-system"
annotations = {"eks.amazonaws.com/role-arn" = aws_iam_role.ca_iam_role.arn}
}
}
# Cluster Autoscaler Helm Release
resource "helm_release" "cluster_autoscaler" {
name = "cluster-autoscaler"
namespace = "kube-system"
chart = "cluster-autoscaler"
repository = "https://kubernetes.github.io/autoscaler"
set {
name = "autoDiscovery.clusterName"
value = var.cluster_name
}
set {
name = "awsRegion"
value = var.aws_region
}
set {
name = "rbac.serviceAccount.create"
value = "false"
}
set {
name = "rbac.serviceAccount.name"
value = kubernetes_service_account.cluster_autoscaler.metadata[0].name
}
set {
name = "rbac.serviceAccount.annotations.eks.amazonaws.com/role-arn"
value = aws_iam_role.ca_iam_role.arn
}
values = [file("${path.module}/values/ca-values.yaml")]
}
2. Helm Chart 코드
아래는 Horizontal Pod Autoscaler (HPA)를 설정하는 Helm 차트 템플릿이다. 먼저, HPA가 활성화되었는지 여부를 검사하고, 설정된 조건에 따라 자동으로 Pod의 수를 조절하도록 구성하고 설정 내용은 대상 리소스, 최소 및 최대 복제본 수, 그리고 CPU 사용량을 기준으로 한 스케일링 기준이 포함되어있다
# AMZDRAW_DEV_GITOPS/backend/templates/hpa.yaml
# Horizontal Pod Autoscaler(HPA) 설정이 활성화되었는지 확인하는 조건문
{{- if .Values.hpa.enabled }}
apiVersion: autoscaling/v2 # HPA의 API 버전을 지정
kind: HorizontalPodAutoscaler # Kubernetes 리소스 종류를 HPA로 지정
metadata:
name: {{ include "amzdraw.fullname" . }} # HPA의 이름을 설정 헬름 템플릿 함수를 사용하여 이름을 동적으로 결정
labels:
{{- include "amzdraw.labels" . | nindent 4 }} # HPA에 적용할 라벨을 설정. 헬름 템플릿 함수를 사용
spec:
scaleTargetRef: # HPA가 대상으로 하는 리소스 지정
apiVersion: apps/v1 # 대상 리소스의 API 버전
kind: Deployment # 대상 리소스의 종류
name: {{ include "amzdraw.fullname" . }} # 대상 리소스의 이름, 헬름 템플릿 함수 사용
minReplicas: {{ .Values.hpa.minReplicas }} # 최소 복제본(replica) 수를 지정. values.yaml 파일에서 설정값 호출
maxReplicas: {{ .Values.hpa.maxReplicas }}
metrics: # HPA가 스케일링을 결정하는 데 사용할 메트릭 지정
- type: Resource # 메트릭의 유형을 리소스로 지정
resource:
name: cpu # CPU 사용량을 기준으로 스케일링을 결정
target: # 스케일링의 목표 값을 설정
type: Utilization # 스케일링의 목표 유형을 CPU 사용률로 설정
averageUtilization: {{ .Values.hpa.targetCPUUtilizationPercentage }} # CPU 평균 사용률 목표치를 지정. values.yaml 파일에서 설정값 호출
{{- end }}
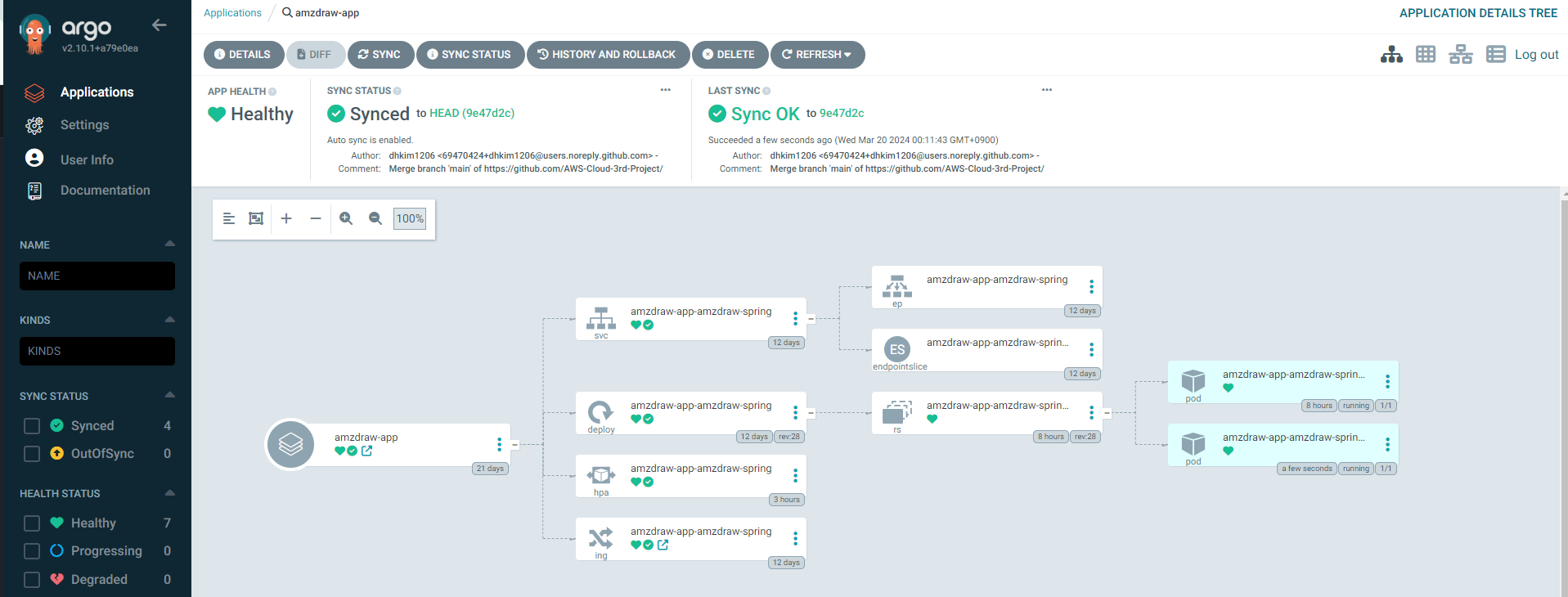
트래픽 주입 전 배포 상황
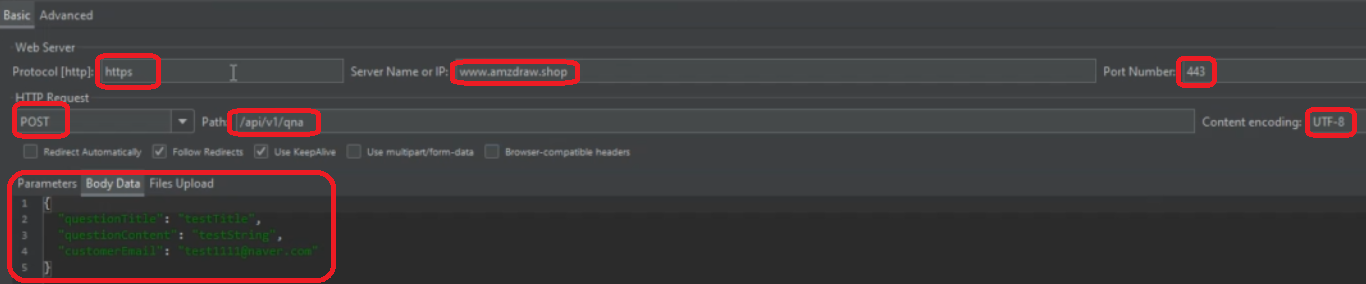
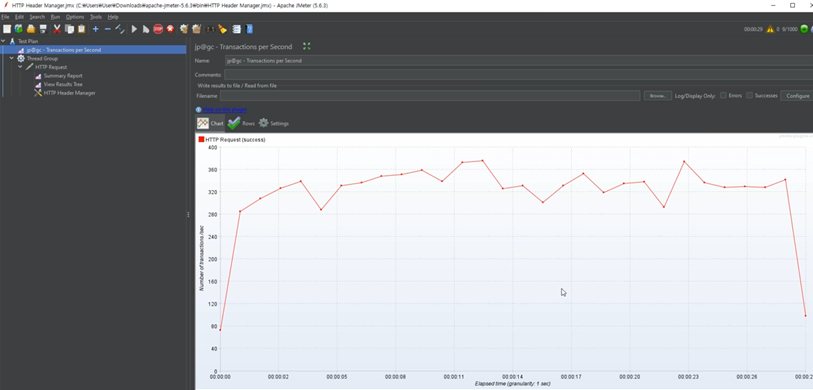
부하 테스트(Jmeter)
HTTPS로 www.amazon.shop의 443 포트로 /api/v1/qna 경로에 POST 요청 전송, 데이터는 Title, Content, Email 형태의 JSON
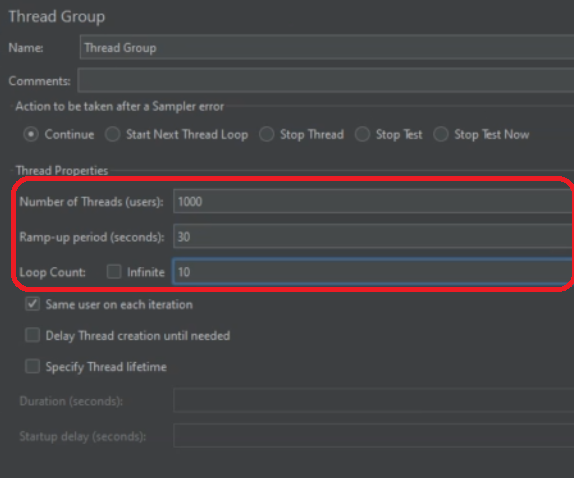
30초 동안 1000개의 사용자(스레드)가 생성, 설정된 요청을 10번 반복
간단히 10,000의 트래픽을 테스트 해보자
트래픽 주입
부하 테스트 결과
HPA로 인한 Pode단에서의 AutoScaling
각 Pod의 메트릭
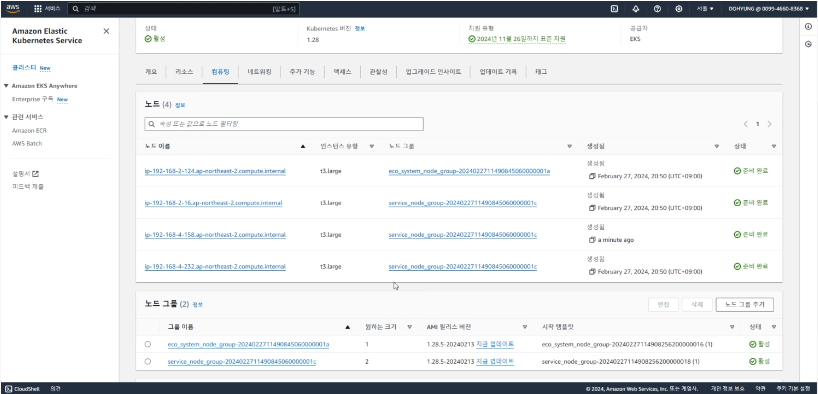
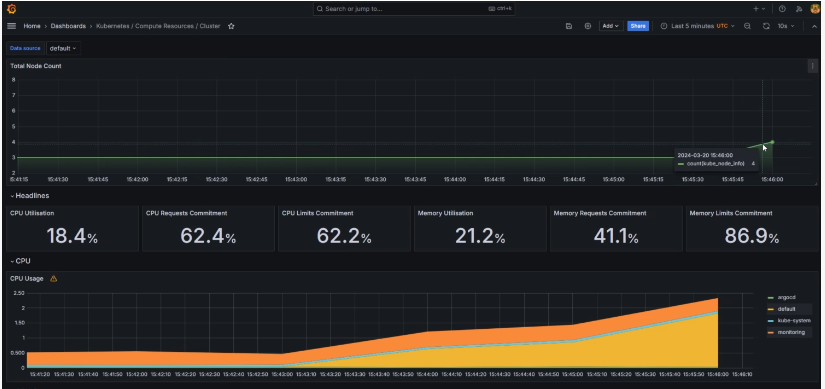
다음은 AWS 콘솔에서의 노드와 그라파나로 메트릭을 시각화한 대시보드다 제일 위의 Total Node Count가 4개로 늘어난 것을 볼 수 있다
단점 (프로비저닝 속도가 느리다)
Karpenter를 써본 입장으로 비교해보자면, CA 방식의 클러스터 오토스케일링은 ASG를 통해서 오토스케일링을 수행하므로 ASG 자체가 인스턴스를 초기화하고 프로비저닝 하는 단계에서 오래걸린다. 실제로 CA와 Karpenter의 프로비저닝 속도를 비교해본 결과 CA는 2분, Karpenter는 19초가 걸렸고, 개선된 상황을 수치로 따져보면 프로비저닝 시간을 84%가 개선되었다.



댓글